探秘数据结构中的图 基础概念与数据处理入门
在计算机科学领域,数据结构是构建高效算法的基石。其中,图(Graph)作为一种非线性数据结构,以其强大的表示能力,在社交网络、路径规划、推荐系统等众多现代应用中扮演着核心角色。本文将带你走进图的世界,从基础概念入手,并初步了解其数据处理的基本思路。
一、图的基础概念:点、线与关系
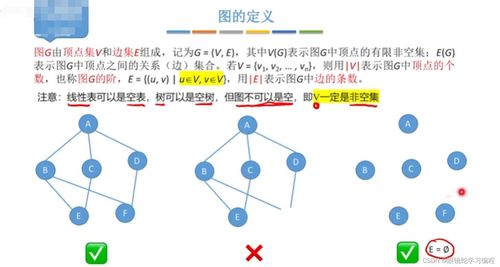
图可以抽象地理解为由一系列顶点(Vertex) 和连接这些顶点的边(Edge) 所组成的集合。这种结构完美契合了我们对事物间复杂关系的描述需求。
- 核心构成元素:
- 顶点/结点:代表实体对象,如社交网络中的用户、地图中的城市。
- 边:代表顶点间的关系或连接。一条边可以连接两个顶点,表示它们之间存在某种关联。
- 图的分类:根据边的性质,图主要分为两大类:
- 无向图:边没有方向,表示双向关系(如微信好友关系)。若顶点A与B相连,则B也与A相连。
- 有向图:边有方向,表示单向关系(如微博的关注关系)。从A指向B的边,并不意味着从B也能到A。
根据边是否带有权重信息,还可分为无权图和带权图。带权图的边拥有一个数值(权重),可以表示距离、成本、强度等(如地图中道路的长度)。
- 关键术语:
- 度:与一个顶点相连的边的数量。在有向图中,进一步分为入度(指向该顶点的边数)和出度(从该顶点指出的边数)。
- 路径与环:顶点序列构成一条路径。如果路径的起点和终点是同一个顶点,则形成一个环。
- 连通性:在无向图中,如果任意两个顶点间都存在路径,则该图是连通图。
二、图的存储:如何将关系数据化?
要在计算机中处理图,首先需要将其存储下来。两种最常用的表示方法是:
- 邻接矩阵:用一个二维数组(矩阵)来表示图。矩阵的行和列分别对应各个顶点。如果顶点 i 到 j 之间存在边,则矩阵中
matrix[i][j]的值为1(或权重值),否则为0(或一个特殊值如无穷大)。
- 优点:直观,判断任意两顶点间是否有边非常快速(O(1)时间复杂度)。
- 缺点:占用空间大(O(V²),V为顶点数),对于边数远少于顶点数的稀疏图来说空间浪费严重。
- 邻接表:为每个顶点维护一个列表(链表、数组等),记录所有与该顶点直接相连的邻接顶点(对于带权图,可同时存储权重)。
- 优点:空间利用率高,只存储实际存在的边,总空间复杂度约为 O(V+E)(E为边数)。尤其适合稀疏图。
- 缺点:判断任意两个特定顶点间是否有边,需要遍历其中一个顶点的邻接表,速度较慢(最坏O(V))。
三、图的数据处理初探:遍历与基础算法
存储了图之后,我们就可以对其进行操作和分析。最基础且关键的操作是图的遍历,即系统地访问图中的每一个顶点。主要有两种策略:
- 广度优先搜索(BFS):从某个起始顶点开始,先访问其所有邻接顶点,然后再逐层向外扩散。它利用队列实现,常用来寻找最短路径(在无权图中)或进行层级遍历。
- 深度优先搜索(DFS):从起始顶点出发,沿着一条路径尽可能深地访问,直到尽头再回溯,选择另一条路径。它利用栈(或递归)实现,常用来探索图的连通分量、检测环或进行拓扑排序。
数据处理示例场景:假设我们有一个表示城市铁路网的图(顶点是车站,边是铁路线)。
使用BFS,可以轻松找到从A站到B站经过站数最少的乘车方案。
使用DFS,可以检查这个铁路网是否所有车站都相互连通(即是否为连通图),或者是否存在某条线路循环运行。
四、
图数据结构为我们理解和建模复杂系统提供了强大的工具。从理解顶点和边的基本概念,到选择邻接矩阵或邻接表进行存储,再到运用BFS、DFS进行基础遍历,这是学习图论算法(如最短路径的Dijkstra算法、最小生成树的Prim/Kruskal算法)的必经之路。掌握这些基础,就如同拿到了解开网络化数据奥秘的第一把钥匙,为后续深入更高级的应用和分析奠定了坚实的基石。
如若转载,请注明出处:http://www.antpainter.com/product/4.html
更新时间:2026-04-22 17:33:53